
刚刚,DeepSeek大更新!终于「开眼」了| 附大量实测
刚刚,DeepSeek大更新!终于「开眼」了| 附大量实测就在刚刚, DeepSeek 上线了识图模式,显示正在灰测中。这意味着讨论了一整年的 DeepSeek 多模态能力,终于来了!目前 DeepSeek 网页版和 App 更新后都有可能被灰测到识图模式,APPSO 第一时间给大家进行了实测。
来自主题: AI资讯
8270 点击 2026-04-29 17:54
 搜索
搜索
就在刚刚, DeepSeek 上线了识图模式,显示正在灰测中。这意味着讨论了一整年的 DeepSeek 多模态能力,终于来了!目前 DeepSeek 网页版和 App 更新后都有可能被灰测到识图模式,APPSO 第一时间给大家进行了实测。
四月真是如风驰电掣:Anthropic 发布了 Opus 4.7,OpenAI 发布了 GPT 5.5,最后,DeepSeek 更新了暌违已久的 V4。三家公司的发布通稿读起来都差不多:跑分又涨了,上下文更长了,推理更强了,代码能力又创了新高。
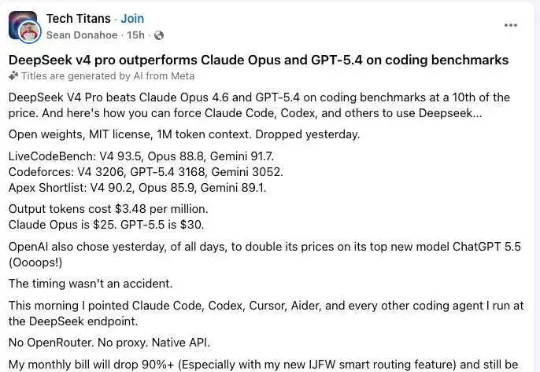
科技博主兼 AI 系统架构师 Sean Donahoe 在今天凌晨发了一条帖子。他写道:这条帖子实际上有两个看点。第一,发帖人是重度 AI 编程用户,却几乎一夜之间完成迁移,月账单会从几千美元降到几百美元。第二,他不只是说便宜,还强调效果没有变差,反而更好:“输出质量提高了,而不是下降,这一点已经通过内部测试以及多个公开基准验证”。
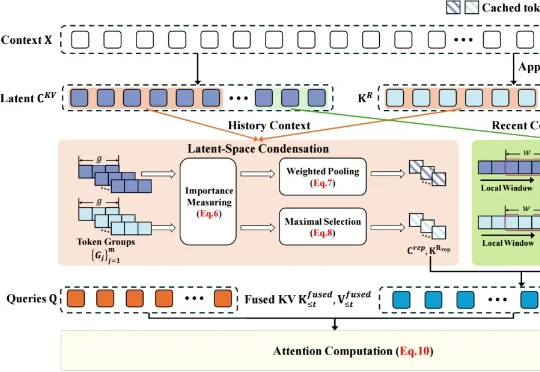
近日,琶洲实验室、华南理工大学、蔻町(AIGCode)等单位科研团队联合提出潜在空间压缩注意力(Latent-Condensed Attention,LCA),研究成果入选 ACL 2026。

OpenClaw最新版本官宣,DeepSeek V4 Flash正式成为默认大模型,250k+星标的全球最火开源Agent框架,把中国最强开源AI推上了C位。

最新消息是,DeepSeek V4 Pro 2.5折的大力度优惠来啦!官方API文档显示,DeepSeek-V4-Pro模型API限时2.5折优惠,优惠期截至2026年5月5日。 具体是这样: 1️⃣百万tokens输入(缓存命中)折后0.25元(原价1元); 2️⃣百万tokens输入(缓存未命中)折后3元(原价12元); 3️⃣百万tokens输出折后6元(原价24元)。

今天上午,DeepSeek V4 发布,直接把这个大模型疯狂更新月推向了最高潮。不过在我翻看 V4 的技术报告的时候,在训练层面看到了一个被大部分人滑过去的名词:Muon 优化器。

Agentic Coding 评测里 V4-Pro 已经到当前开源最佳水平。DeepSeek 公司内部已经把 V4 作为默认编码模型,反馈是优于 Sonnet 4.5,交付质量接近 Opus 4.6 的非思考模式,和 Opus 4.6 的思考模式还有差距。这次还专门为 Claude Code、OpenClaw、OpenCode、CodeBuddy

由智源研究院牵头研发的众智 FlagOS 第一时间对两个“巨无霸”模型进行全量适配,已经完成 DeepSeek-V4-Flash 在8款以上 AI 芯片上的全量适配与推理部署,包括海光、沐曦、华为昇腾、摩尔线程(FP8)、昆仑芯、平头哥真武、天数、英伟达(FP8)等芯片。FlagOS 同时正在推进 DeepSeek-V4-Pro 模型在多个芯片的迁移适配,晚些时间开源出来,敬请期待。
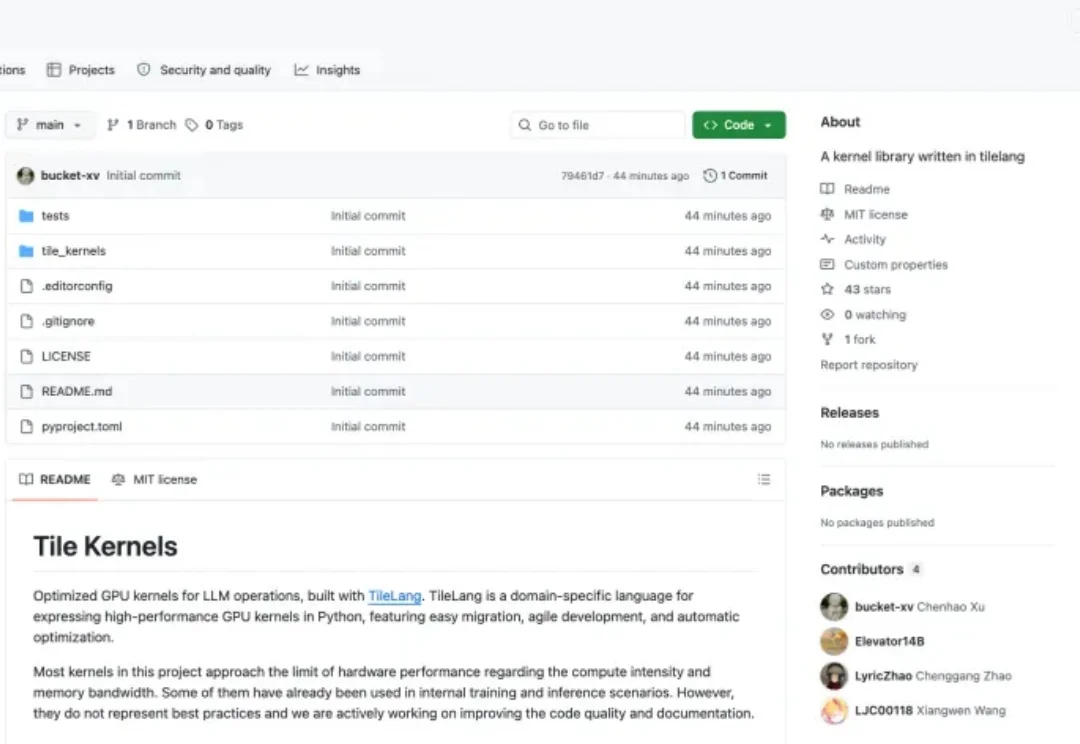
就在刚刚,DeepSeek 的 GitHub 开始了频繁更新,上线开源了一个新的代码库 Tile Kernels,同时并对 DeepEP 代码库进行了更新,上线了 DeepEP V2。距离上次 DeepSeek 悄悄更新 Mega MoE、FP4 Indexer 还不到一周。